Keras 模型中使用预训练的 gensim 词向量和可视化
最近因为公司业务需求开始研究 NLP,Word Embedding 是 NLP 中最为基础的处理方式之一。Word Embedding 比较流行的有 Word2vec 和 GloVe 等方案。
- 2020-05-16更新 - 根据 TensorFlow 官方文档,提供一个更简洁的方案,见可视化脚本 v2。
Keras 模型中使用预训练的词向量
Word2vec,为一群用来产生词嵌入的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系。该向量为神经网络之隐藏层。
https://zh.wikipedia.org/wiki/Word2vec
在这篇 [在Keras模型中使用预训练的词向量](https://keras-cn.readthedocs.io/en/latest/blog/ word_embedding/) 讲述了如何利用预先训练好的 GloVe 模型,本文基本大同小异。只写一些不同的地方,更想的可以看这篇文章。
总体思路就是给 Embedding 层提供一个 [ word_token : word_vector] 的词典来初始化向量,并且标记为不可训练。
解析 word2vec 模型,其中:
word2idx保存词语和 token 的对应关系,语料库 tokenize 时候需要。embeddings_matrix存储所有 word2vec 中所有向量的数组,用于初始化模型Embedding层
1 | import numpy as np |
使用方法:
1 | from keras.layers import Embedding |
Tensorboard 可视化 Keras 模型
Tensorflow 提供了超级棒的可视化工具 TensorBoard,详细的介绍请看 - TensorBoard: Visualizing Learning
Keras 模型记录训练进度到 Tensorboard 非常方便,直接使用 Keras 封装好的 Tensorboard 回调 即可。
不过这里有个小细节,如果想对比多次运行的效果,一定要每次记录在 log 目录下的不同的子目录。
1 | logdir = "./logs/{}".format(run_name) |
然后运行 tensorboard --logdir='./logs/' 即可看到相应的运行记录。就能看到以下的记录:
然而当打开 Embeddings 看词向量可视化效果时候发现所有的节点全部用数字表示的,密密麻麻的数字根本看不懂…
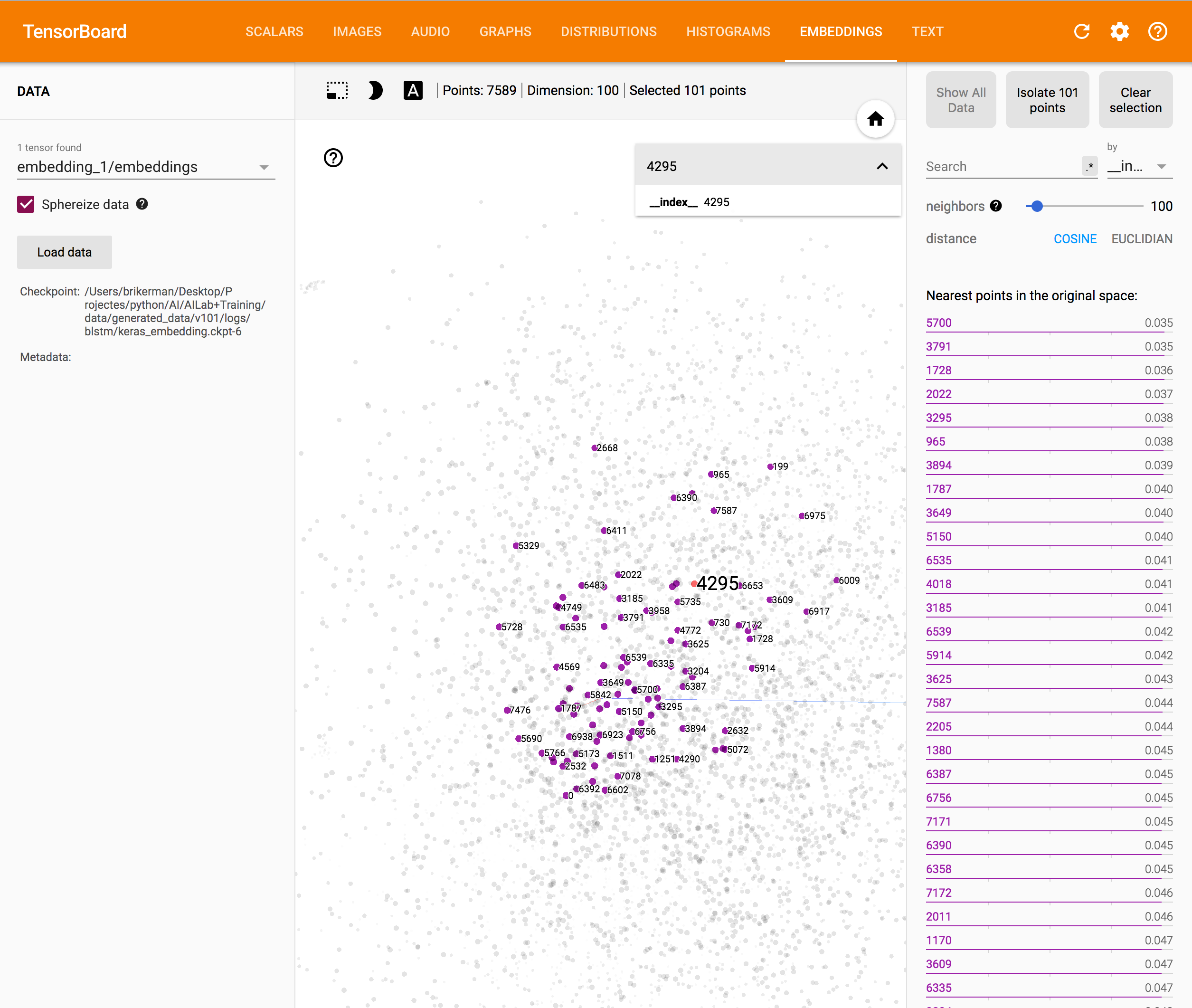
这些数字是我们 tokenize 时候使用的 id,现在利用之前保存的 word2idx 字典来生成该 Embedding 的 metadata.
1 | meta_file = "w2v_metadata.tsv" |
再次训练后运行 tensorboard --logdir='./logs/' ,然后可以看到带上中文标签的 Embedding 可视化效果。
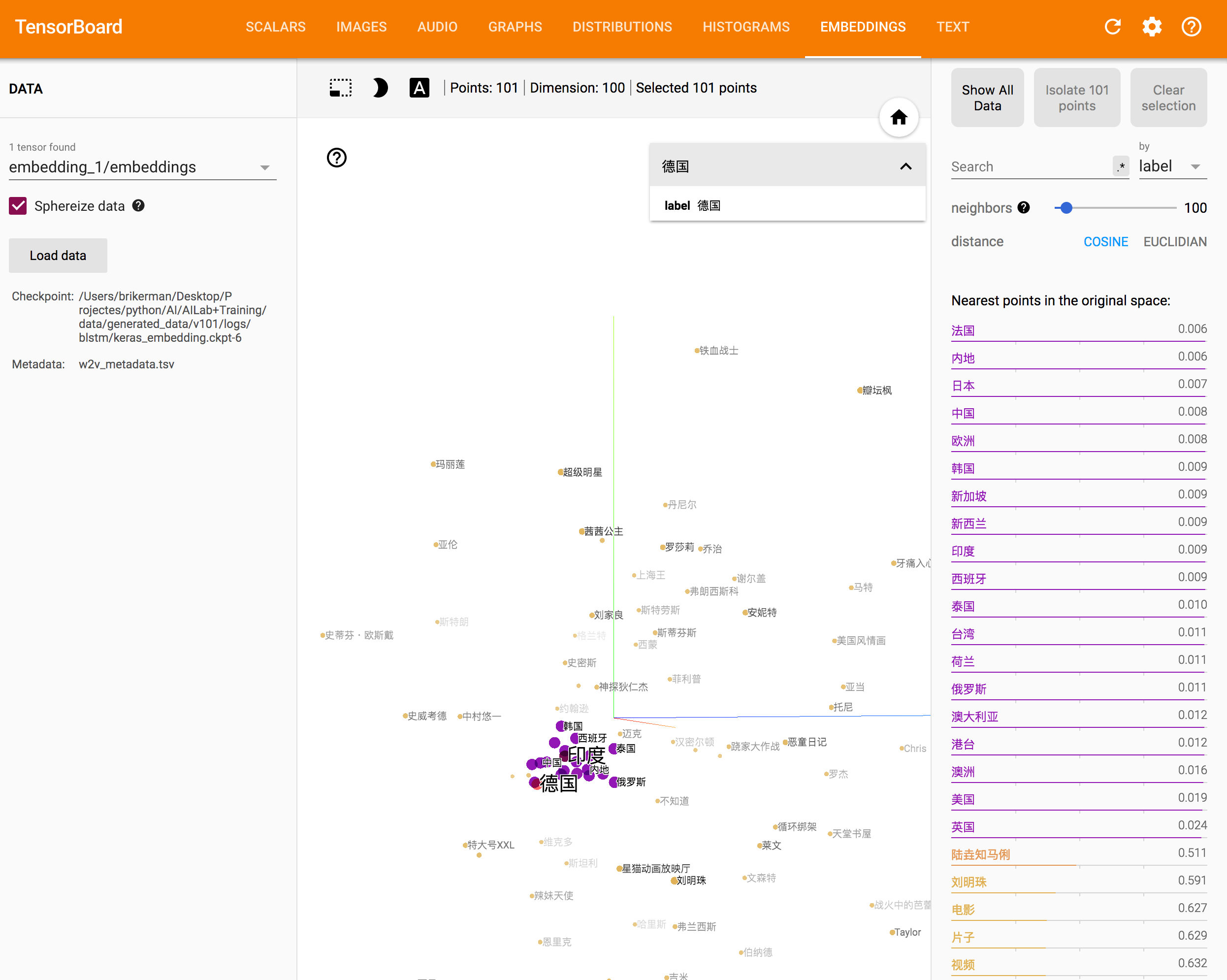
直接可视化 word2vec 模型
上面的可视化方法需要在 keras 建模并且训练,如果想直接可视化,可以利用 w2v_visualizer.py 这个脚本,使用方法很简单。
可视化脚本 v2
2020-05-16更新 - 根据 TensorFlow 官方文档,提供一个更简洁的方案。
根据上述代码生成 vecs.tsv 和 meta.tsv 两个文件后,打开 Embedding Projector:
- 点击左侧 Data 下的 “Load”。
- 分别上传
vecs.tsv和meta.tsv文件,关闭上传窗口。
即可在 Embedding Projector 可视化词向量。